Wenn ein Programm auf mehr Teams skaliert, bin ich regelmäßig dabei, das Team-Setup zu gestalten — und regelmäßig die falsche Person dafür.
Nicht weil mir die Erfahrung fehlt. Sondern weil das Wissen, das diese Entscheidung treffen sollte, nicht bei mir liegt. Es liegt in den Domänen.
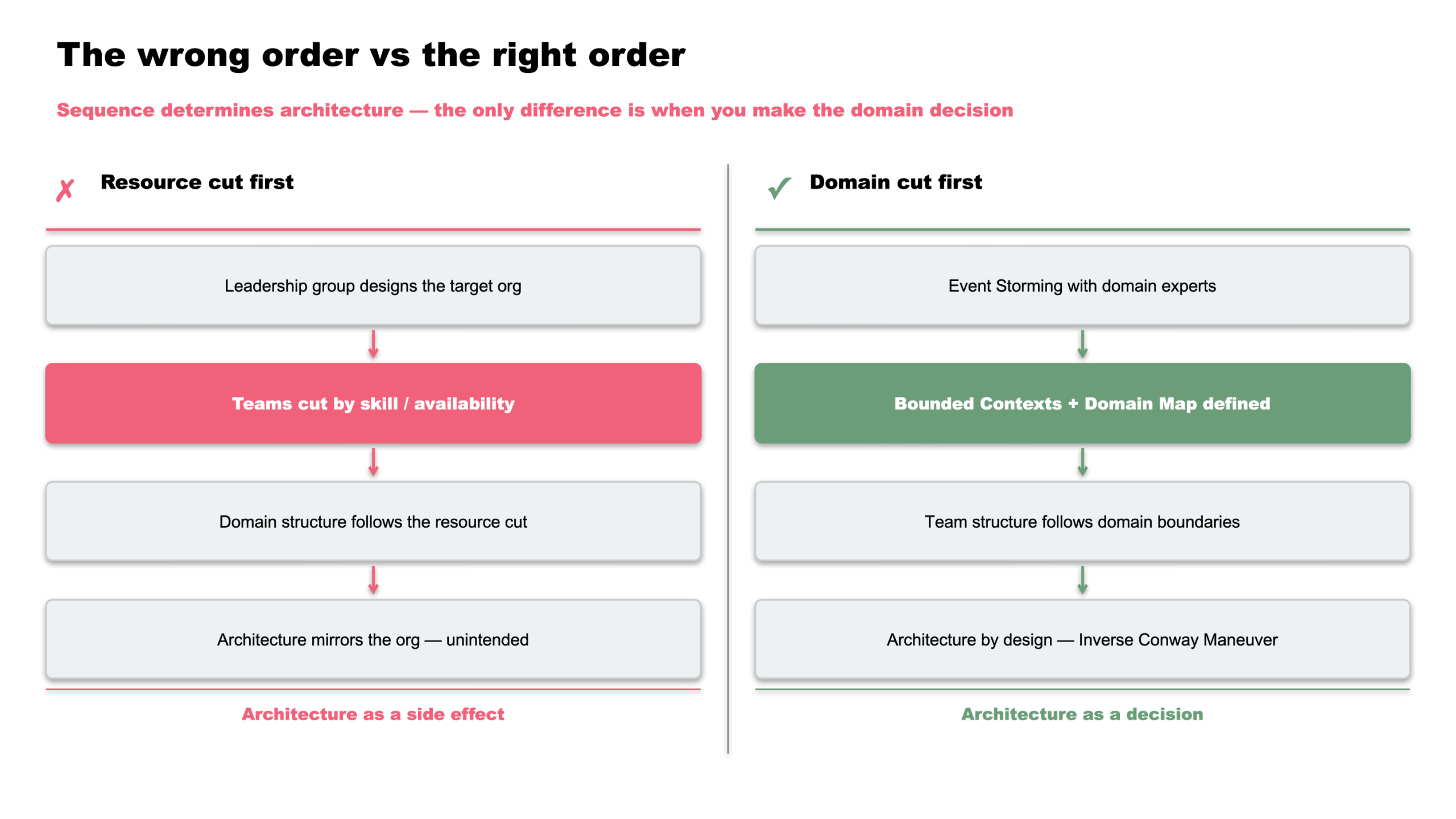
Wer ein großes Modernisierungsprogramm skaliert, hat oft denselben Instinkt: mehr Teams aufbauen, den Scope aufteilen, die verfügbaren Leute den neu definierten Bereichen zuordnen. Eine Führungsgruppe einsetzen, die den Überblick hat und entscheiden kann, wer gebraucht wird. Das klingt nach vernünftigem Programm-Management.
Es ist strukturell falsch — und die Ursache ist architektonischer, nicht organisatorischer Natur: Solange die Domänengrenzen ungeklärt sind, treibt die Ressourcenzuteilung die Architektur. Das ist Conway’s Law. Und wir wissen heute genau, was daraus folgt.
Die Annahme, auf der der klassische Ansatz beruht
Der klassische Ansatz funktioniert so: Eine Führungsgruppe — Programm-Manager, Architekten, manchmal externe Berater — entwirft die Zielorganisation. Teams werden nach Fähigkeiten, technischen Schichten oder Ressourcenverfügbarkeit strukturiert. Dann werden die verfügbaren Personen in diese Struktur eingepasst.
McKinsey formuliert den Ausgangspunkt in ihrer Agile-Transformationsmethodik klar: „Die meisten Transformationen beginnen damit, das Verständnis und die Ambitionen des Top-Teams aufzubauen.“ Das klingt plausibel. Das Problem liegt in der Annahme darunter: dass das Wissen darüber, wie gute Teamstrukturen aussehen, oben sitzt.
Das tut es nicht. Und in einer Transformation der Komplexität, die jahrzehntealte Legacy- oder gar Mainframe-Systeme mit sich bringen, ist dieser Fehler besonders folgenreich.
Warum das Wissen in den Domänen liegt — und was Conway damit zu tun hat
Die Teams, die täglich mit den Systemen und Geschäftsprozessen arbeiten, verstehen die Abhängigkeiten des bestehenden Systems besser als jede Führungsgruppe. Sie wissen, welche Teile des Systems eng gekoppelt sind. Sie wissen, wo die wirklichen Schnittstellenprobleme liegen.
Melvin Conway formulierte 1968, was wir heute als Conway’s Law kennen: Organisationen, die Systeme bauen, produzieren zwangsläufig Designs, die ihre eigene Kommunikationsstruktur widerspiegeln. Das ist keine Metapher. Es ist eine Kausalaussage. Wenn ich Teams entlang technischer Schichten oder nach Verfügbarkeit schneide, erhalte ich eine Systemarchitektur, die diese Aufteilung spiegelt — nicht die, die ich wollte.
MacCormack, Rusnak und Baldwin haben das 2008 in einer Studie der Harvard Business School empirisch untermauert. Sie untersuchten, wie eng Organisationsstruktur und Produktarchitektur korrelieren — die sogenannte Mirroring Hypothesis. Das Ergebnis: Produkte aus lose gekoppelten Organisationen sind rund achtmal modularer als solche aus eng gekoppelten. Schlechtes Organisationsdesign erzeugt schlechte modulare Architektur — nicht als Nebeneffekt, sondern als direkte Konsequenz.
Für ein großes Modernisierungsprogramm — die Art, mit der ich arbeite — bedeutet das: Die Entscheidung, wie Teams geschnitten werden, ist keine Ressourcenfrage. Sie ist eine architektonische Entscheidung. Und sie muss getroffen werden, bevor die Ressourcenplanung beginnt.
Der Inverse Conway Maneuver: Architektur zuerst
Wer die Architektur, die er will, bewusst erzeugen möchte, muss die Teamstruktur entsprechend gestalten — nicht umgekehrt. Statt Teams zu definieren und zu hoffen, dass die Architektur folgt, kehren wir die Reihenfolge um. Wir beginnen mit der Frage: Welche Architektur brauchen wir? Welche Domänen hat das System, wie stark sind ihre internen Abhängigkeiten, wie lose ihre Verbindungen nach außen?
Diese Umkehrung — in der Literatur als Inverse Conway Maneuver bekannt und im Thoughtworks Technology Radar als etablierte Technik gelistet — ist der zentrale Hebel beim Skalieren von Delivery-Programmen.
In der Praxis funktioniert das über Domänenanalyse. Wir nutzen Domain-Driven Design: Event-Storming-Sessions mit Domänenexperten aus dem Business, Bounded-Context-Definitionen, Context Maps. Das Ziel ist immer dasselbe: eine Domänenkarte, die zeigt, welche Bereiche des Systems intern stark korreliert sind und möglichst wenige externe Abhängigkeiten haben.
Diese Karte ist der Ausgangspunkt für den Teamschnitt — nicht die freien Slots in den Kalendern der Leute.
Skelton und Pais entwickeln in Team Topologies einen komplementären Gedanken: Jedes Team hat eine kognitive Last — einen maximalen mentalen Overhead, den es tragen kann. Stream-aligned Teams, die einem einzigen Wertstrom folgen, minimieren Übergaben und halten diese Last beherrschbar. Top-down-Strukturen, die Fähigkeiten nach Verfügbarkeit verteilen, ignorieren diese Grenze regelmäßig.
Ein schichtenbasierter Schnitt erzwingt Übergaben quer durch alle Teams für jede fachliche Änderung. Ein domänenbasierter Schnitt eliminiert diese Abhängigkeit vollständig.
Was das konkret in einem komplexen Programm bedeutet
Ein großes Modernisierungsprogramm — mit einem Legacy- und manchmal Mainframe-System, in dem Logik über Jahrzehnte zu einer praktisch untrennbaren Einheit gewachsen ist — bringt genau diese Herausforderung mit sich.
Die Modernisierungsstrategie, die wir in solchen Programmen empfehlen, ist konsistent: Domäne für Domäne aufbauen, dem Strangler-Fig-Muster folgend, Slice für Slice. Mit einem Kern beginnen, der die Architektur unter realen Bedingungen beweist — bevor das Programm auf weitere Domänen skaliert. Die zentralen Fachdomänen liefern die Struktur; ihre Grenzen müssen vor dem Teamschnitt feststehen.
Genau hier greift die Conway-These unmittelbar: Der Domänenschnitt muss dem Ressourcenschnitt vorausgehen. Team-Ownership folgt aus der Domänenstruktur — nicht aus der Kapazitätsverfügbarkeit.
Deshalb beginnt die erste Phase eines solchen Programms mit Event Storming und Domain-Driven Design. Nicht als methodisches Ritual. Sondern weil dieser Schritt das Fundament für jede nachfolgende Entscheidung legt: Welche Bounded Contexts entstehen innerhalb der Kerndomänen? Wo verlaufen die Grenzen — und wer übernimmt ihre Ownership?
Ein konkretes Beispiel aus der Praxis: Kernversicherungsprozesse — Neugeschäft und unterjährige Vertragsänderungen — spannen jeweils mindestens drei Fachdomänen in komplexen Systemen auf. Eine Anfrage löst die Preisfindung in einer Domäne aus; ein akzeptierter Antrag stellt eine Police in einer zweiten aus; und das bindende Ereignis (Inkrafttreten des Versicherungsschutzes) treibt nachgelagerte Pflichten — Abrechnung, Korrespondenz, Provisionen — die in weiteren Kontexten liegen. Genau diese domänenübergreifenden Übergaben macht Event Storming sichtbar — und genau das ist der Nachweis, den ein Team braucht, um zu entscheiden, wo Bounded-Context-Grenzen gezogen werden sollen. Hätte das Team diesen Schnitt vor dieser Analyse vorgenommen, hätte es diese Übergaben entweder ignoriert oder willkürlich quer durch sie geschnitten.
Eine Führungsgruppe am Reißbrett kann diese Fragen nicht beantworten. Sie entstehen durch die Zusammenarbeit mit den Domänenexperten aus dem Business — in den Workshops, über die Event Maps, durch die gemeinsame Schärfung der Bounded Contexts. Erst wenn diese Karte existiert, entscheidet sie, wie Teams geformt werden und wie Verantwortung verteilt wird.
Self-Selection: das Team entscheiden lassen
In einigen Programmen gehen wir einen Schritt weiter — und das ist der Schritt, der den größten Widerstand erzeugt, wenn wir ihn erstmals vorschlagen.
Statt verfügbare Personen zentral den neu definierten Domänenteams zuzuweisen, lassen wir das Team sich selbst organisieren. Die Domänenkarte liegt auf dem Tisch. Die verfügbaren Slots sind transparent. Die Rahmenbedingungen sind klar: Fähigkeiten, Erfahrungsverteilung, Seniorität. Und dann fragen wir die Leute, wo sie sich sehen.
Die Belege für diesen Ansatz sind konsistent — auch wenn sie aus Fallstudien statt aus kontrollierten Experimenten stammen. Sandy Mamoli und David Mole haben Self-Selection durch ihre Arbeit bei Trade Me und in ihrem Buch Creating Great Teams dokumentiert: Teams, die sich ohne direkte Managementzuweisung formiert hatten, wurden über zwei Jahre zu hochleistungsfähigen Teams — mit minimalen nachträglichen Anpassungen. Martin Lohmanns Erfahrungsbericht über SimCorps Product Division — ein SAFe-Rollout mit rund 550 Personen, die 55+ Teams über sieben ARTs bildeten — zeigt dasselbe Muster in größerem Maßstab. Bei New Relic wurden rund 50 Software-Teams vollständig durch Selbstorganisation unter vordefinierten Rahmenbedingungen neu geformt. Die Organisatoren beschrieben das Ergebnis danach als „way more successful than anybody anticipated“. Und ich habe es selbst funktionieren sehen.
Ein unerwarteter Nebeneffekt: Die Leute wählten Kollegen, mit denen sie arbeiten wollten. Das klingt simpel — und das ist es. Wer wählen darf, übernimmt Ownership. Wer zugewiesen wird, wartet ab.
Der natürliche Moment für eine Self-Selection-Session ist der Abschluss der ersten Programmphase: Sobald die Bounded-Context-Karte der Kerndomänen steht, sind die Team-Slots und ihre Verantwortungsbereiche transparent genug, damit die Leute eine informierte Wahl treffen können.
Die Ausführung entscheidet: Self-Selection erfordert aktive Moderation. Ohne sie entstehen keine guten Teams — das zeigen die Fallstudien genauso klar wie die Erfolge.
Je weiter sich ein Programm von Self-Selection in Richtung zentraler Zuweisung bewegt, desto weniger Ownership fühlen die Leute — und desto mehr Nachjustierung braucht die Struktur im Nachhinein.
Wie das in den breiteren Diskurs passt
Das Spotify-Modell taucht in jeder Diskussion über Team-Skalierung auf. Joakim Sundén, einer der Agile Coaches, die das Modell während seiner Entstehung begleiteten, beschrieb es als „teils Ambition, teils Annäherung“ — nie vollständig umgesetzt, immer ein Wunschbild. Was Unternehmen kopierten, war die Struktur: Squads, Tribes, Chapters. Was sie ignorierten, war die Kultur — echte Autonomie, psychologische Sicherheit, die Bereitschaft, Fehler zuzulassen. Struktur ohne Domänenlogik und ohne echte Dezentralisierung ist nur ein Label.
Der Unterschied liegt nicht im Organigramm. Er liegt darin, wer das Wissen hält, das den Schnitt informiert.
Was das in der Praxis bedeutet
Skalierung ist kein Ressourcenproblem. Es ist ein Architekturproblem.
Neue Teams hinzuzufügen, ohne die Domänenstruktur des Systems zuerst zu verstehen, baut eine Organisationsform auf, die — per Conway’s Law — eine Systemarchitektur erzeugt. Und diese Architektur wird nicht die sein, die man wollte. Die HBS-Studie zeigt, dass dieser Effekt real und messbar ist — nicht theoretisch.
Für ein komplexes Modernisierungsprogramm bedeutet das konkret: Die Investition in Event Storming und Domain-Driven Design zu Beginn ist kein methodisches Pflichtprogramm. Sie ist die Voraussetzung dafür, dass die Teams, die in späteren Phasen skalieren, entlang der richtigen Grenzen arbeiten. Domain Ownership, Bounded Contexts, Context Maps — diese Artefakte sind nicht nur Architekturdokumente. Sie sind das Fundament der Teamorganisation.
Wer entscheidet, wo die Domänengrenzen liegen sollen? Jemand in der Führungsgruppe, der den Scope kennt — oder die Leute, die täglich mit dem System arbeiten und wissen, wo die echten Kopplungen sind?
In den Programmen, mit denen ich arbeite, wird diese Frage regelmäßig implizit beantwortet, bevor sie je gestellt wird. So fängt das Problem meistens an.
Quellen und weiterführende Literatur
Thoughtworks / Inverse Conway Maneuver
Conway’s Law — empirische Grundlage
Team Topologies
Self-Selection
Spotify — genauer hingeschaut
McKinsey Agile